בפרק זה נלמד על מבחני השערות פשוטים שניתן להפעיל ב-R. מטבע הדברים, מכיוון ש-R היא שפה סטטיסטית יש ערב רב של מבחני השערות פרמטרים וא-פרמטריים, שבוחנים השערות שונות במצבים שונים, אבל בספר זה נתמקד במבחני ההשערות שיימצאו בקורס מבוא לסטטיסטיקה (ואולי עוד קצת).
מטרת הפרק היא לא לספק את התיאוריה. לצורך השלמות תיאורתיות, אני ממליץ לקרוא את (Walpole et al. 1993).
מטרת הפרק שלפניכם היא לתת כלים מעשיים לביצוע מבחני השערות, בפרט נדון במקרים הבאים:
מבחני השערות על תוחלת
מבחני השערות על שונות
מבחני השערות על אי-תלות
מבחני השערות על התפלגות
6.1 מבחן השערות על תוחלת
אחד מהפרמטרים החשובים של התפלגויות הוא התוחלת. ישנו קשר הדוק בין תוחלת ובין ממוצע - כאשר אנחנו מבצעים דגימה מתוך אוכלוסיה, ממוצע המדגם הוא אמד המייצג את התוחלת.
נדגים זאת בעזרת מדגם הפינגויינים שראינו בפרק הקודם:
לכל אחד מזני הפינגויינים ממוצע שונה לאורך המקור. לדוגמה, פינגויינים מסוג Adelie הם בעלי מקור באורך ממוצע 38.8 מ”מ. בפועל מדובר בממוצע המחושב על מדגם של 151 תצפיות, וסביר להניח שהתוחלת בכלל אוכלוסית הפינגויים מזן Adelie היא קצת שונה. לדוגמה, תוחלת של 38 מ”מ, יכולה להביא לכך שממוצע על פני דגימה של 151 תצפיות יהיה 38.8 מ”מ.
המטרה של מבחן השערות על התוחלת היא לעזור לנו לקבוע ברמת שגיאה של \(\alpha\) (אשר בדרך כלל נקבעת כ-5% שגיאה), האם התוחלת היא בעלת ערך מסוים\(\mu_0\), בהינתן תוצאות המדגם שלנו.
צורת הסתכלות אחרת היא בניית רווח בר סמך לתוחלת, או במילים אחרות, מה הטווח הסביר שבו נמצאת התוחלת בהינתן תוצאות המדגם.
בשלב זה נתייחס למדגם אחד, ולאחר מכן נכליל את ההסתכלות לשני מדגמים.
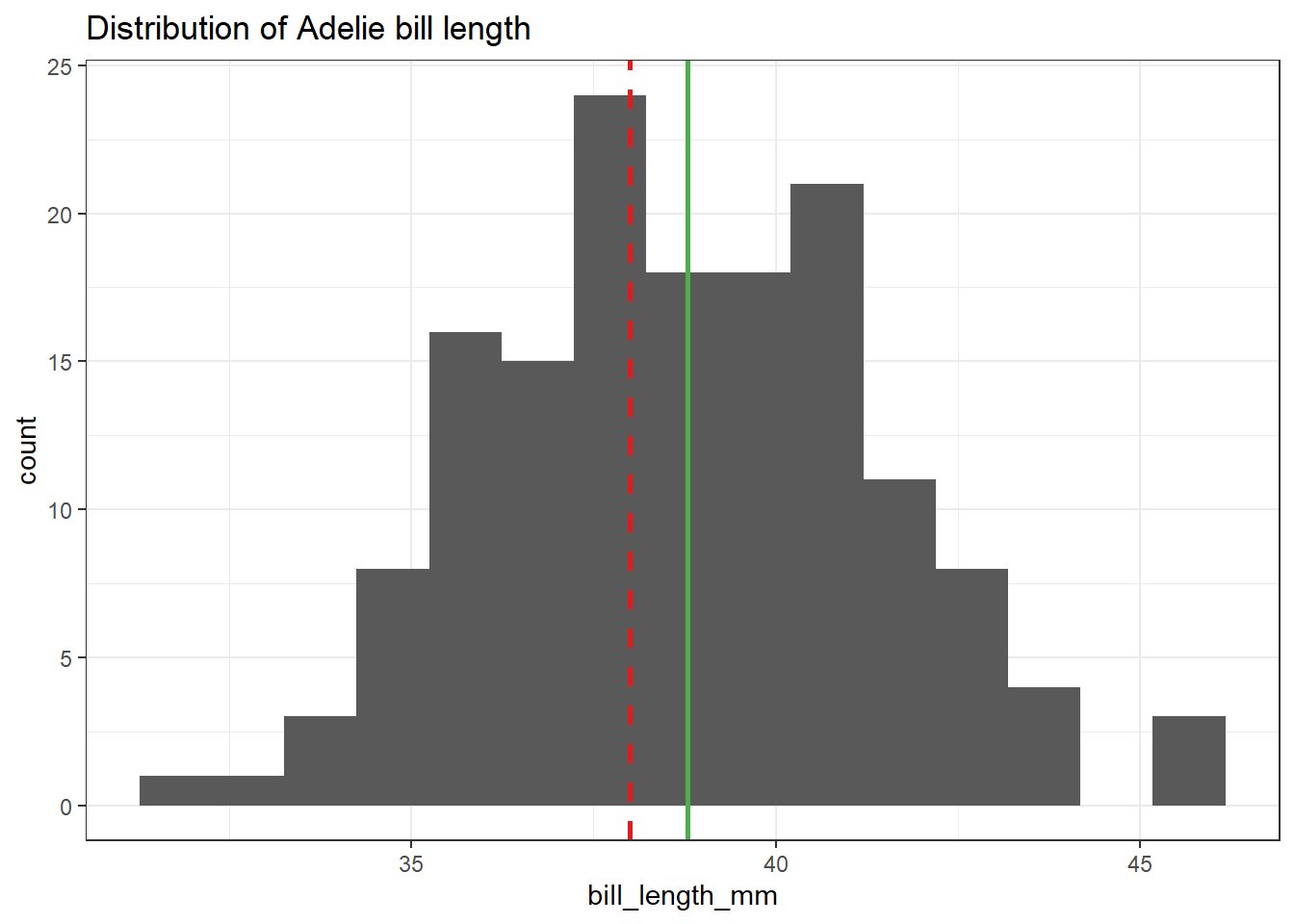
התרשים הבא מציג את התפלגות אורך המקור של פינגויינים מזן Adelie באמצעות היסטוגרמה.
על ההיסטוגרמה הלבשנו שני קווים אנכיים: הממוצע בפועל בירוק (38.3913), והערך שאותו נבחן כתוחלת (38) באמצעות מבחן השערות.
adelie <- penguins %>%filter(species =="Adelie") %>%filter(!is.na(bill_length_mm))ggplot(adelie, aes(x = bill_length_mm)) +geom_histogram(bins =15) +geom_vline(xintercept =38, color ="#E41A1C", linewidth =1, linetype =2) +geom_vline(xintercept =mean(adelie$bill_length_mm), color ="#4DAF4A", linewidth =1) +ggtitle("Distribution of Adelie bill length")
נשתמש בפקודת t.test על מנת לייצר רווח בר סמך (או מבחן השערות) לתוחלת אורך המקור של פינגויינים מזן Adelie.
נבנה את רווח בר הסמך ברמת ביטחון של 95% (כלומר רמת הוודאות של הדיווח שנקבל היא 95%, או 5% שגיאה). כמו כן, נבחן האם ייתכן שהתוחלת הינה 38, למרות שהתצפיות במדגם בעלות ממוצע של 38.8.
adeliettest <-t.test(adelie$bill_length_mm, alternative ="two.sided",mu =38, conf.level =0.95)adeliettest
One Sample t-test
data: adelie$bill_length_mm
t = 3.6513, df = 150, p-value = 0.0003598
alternative hypothesis: true mean is not equal to 38
95 percent confidence interval:
38.36312 39.21966
sample estimates:
mean of x
38.79139
פרשנות תוצאות המבחן: אנו דוחים את השערת ה-0 שהתוחלת הינה 38. להלן הסבר מפורט לפלט:
בראש הפלט מופיע סוג המבחן שהופעל (One Sample t-test), כלומר מבחן t עבור מדגם יחיד (יש גם מבחנים עבור שני מדגמים מזווגים, ושני מדגמים לא-מזווגים, מיד נדגים).
בשורה השניה מופיע הדאטה שבו השתמשנו.
בשורה השלישית ההשערה האלטרנטיבית שנבחנה (המכונה \(H_1\) . במקרה זה הגדרנו בארגומנט alternative מבחן השערה דו-צדדי, כלומר: \(H_1: \mu\neq38\).
בשורה הרביעית ערך \(T\) של המבחן (המכונה גם סטטיסטי המבחן), במקרה זה ערכו הוא 3.6513, ובנוסף מספר דרגות החופש (df), וערך המובהקות (p-value). ערך p-value במקרה זה הינו מתחת ל-0.05 מה שמעיד על כך שעלינו לדחות את השערת ה-0 (\(H_0: \mu=38\)).
בשורה הבאה (ובזו שאחריה) מופיע הרווח בר סמך לתוחלת. במקרה זה הרווח בר סמך ברמת בטחון של 95% מעיד על כך שתוחלת אורך המקור של הפינגויין מהזן הנבחן נמצאת בין 38.36 לבין 39.22. ניתן לשים לב שהתוחלת אותה בחנו בהשערת ה-0 ($\mu=38$) נמצאת מחוץ לטווח זה, וזה עולה בקנה אחד עם הדחיה שתיארנו בסעיף קודם בהתייחס לערך ה-p-value.
לבסוף מופיע הממוצע עצמו של המשתנה (38.7914).
מעבר ממבחן דו-צדדי למבחן חד-צדדי
היעזרו בתיעוד הפקודה t-test ושנו את הארגומנט alternative על מנת לבצע את המבחן הסטטיסטי:
\[
H_0: \mu=38
\]
\[
H_1: \mu>38
\]
מה תוצאת המבחן? מה המסקנה?
6.2 שני מדגמים לא-מזווגים
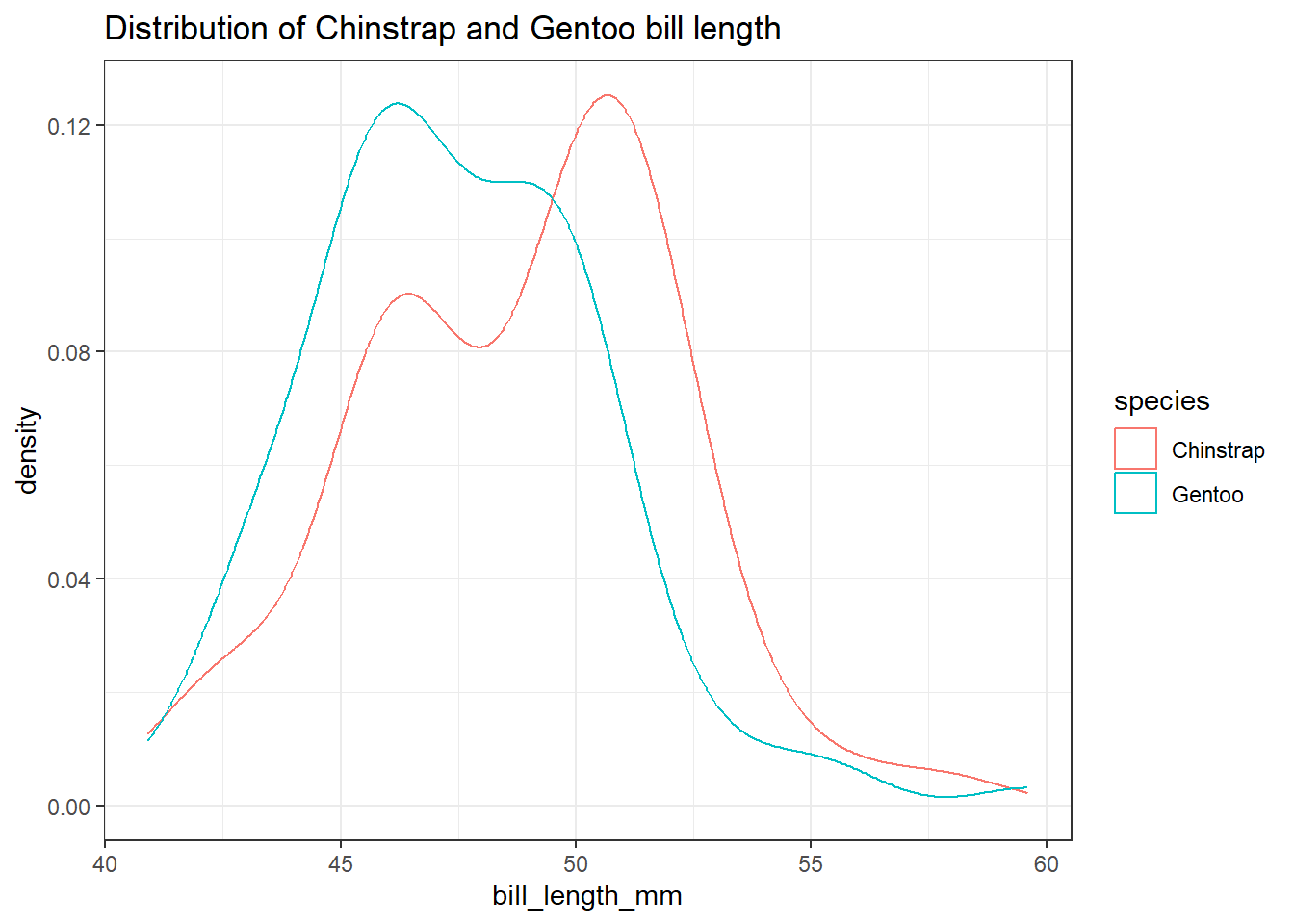
כעת נפנה למבחן t-test שבו נשתמש כאשר ברצוננו להשוות בין שני מדגמים, לא מזווגים. לדוגמה על מנת לבחן האם ניתן לדחות את ההשערה שאורך המקור של פינגויינים מזן Chinstrap ואורך המקור של פינגויינים מזן Gentoo שווים (כפי שראינו ערכיהם דומים יחסית).
ראשית, נציג את ההתפלגות של שני הזנים בתרשים הבא:
chin_gentoo <- penguins %>%filter(!is.na(bill_length_mm)) %>%filter(species !="Adelie")ggplot(chin_gentoo,aes(x = bill_length_mm, color = species)) +geom_density() +ggtitle("Distribution of Chinstrap and Gentoo bill length")
התרשים ממחיש לנו הבדלים בין התפלגות אורך המקור של שני הזנים (ובהמשך הפרק נראה איך בוחנים הבדלים בין שתי התפלגויות), אך כעת נרצה לבחון את ההבדלים בין ממוצעי אורך המקור של כל זן. נשתמש בפקודה t-test אך בצורת הפעלה מעט שונה מזו שבה השתמשנו במקרה של מדגם יחיד.
Welch Two Sample t-test
data: bill_length_mm by species
t = 2.706, df = 129.22, p-value = 0.00773
alternative hypothesis: true difference in means between group Chinstrap and group Gentoo is not equal to 0
95 percent confidence interval:
0.3572698 2.3006212
sample estimates:
mean in group Chinstrap mean in group Gentoo
48.83382 47.50488
צורת ההפעלה שבה השתמשנו מגדירה נוסחה ודאטה. הנוסחה היא bill_length_mm ~ species, כלומר בחן את אורך המקור לפי המשתנה species (במקרה זה, חייבים שלמשתנה המסביר species יהיו בדיוק שתי רמות, אחרת נקבל שגיאה).
קיבלנו דחיה של השערת ה-0, כלומר ניתן לדחות את ההשערה שתוחלת אורך המקור בין שני הזנים שווה. ברמת מובהקות של 0.00773.
הרווח בר סמך מתייחס להפרש בין התוחלות, קרי, ברמת ביטחון של 95% ההפרש בין התוחלות נע בין 0.357 לבין 2.301 (לטובת Chinstrap שבעלי אורך מקור גדול יותר).
הפקודה שהרצנו משתמשת במבחן המניח שונות שונה, ניתן לשנות זאת על ידי הוספת הארגומנט var.equal=TRUE.
Two Sample t-test
data: bill_length_mm by species
t = 2.7694, df = 189, p-value = 0.006176
alternative hypothesis: true difference in means between group Chinstrap and group Gentoo is not equal to 0
95 percent confidence interval:
0.3823625 2.2755285
sample estimates:
mean in group Chinstrap mean in group Gentoo
48.83382 47.50488
6.3 שני מדגמים מזווגים
נדגים כעת מבחן t-test שבו משתמשים כאשר יש לנו שני מדגמים אשר מזווגים ביניהם. מדגמים מזווגים הם מדגמים אשר לכל ערך במדגם הראשון ניתן לזווג ערך במדגם השני (באופן חד-חד ערכי). משום כך, מדגמים מזווגים תמיד יהיו שווים בגודלם. הדוגמה ה”קלאסית” למדגמים מזווגים הם מחקר שבו יש שלב של “לפני” ושלב של “אחרי”: הם מזווגים משום שניתן להצמיד אחרי-לפני עבור כל נדגם. במקרים בהם רוצים לבחון התערבות מסוימת אז אפשר להשוות את ההפרשים של אחרי-לפני ולראות האם ההפרשים שונים באופן מובהק מ-0 (ואז זה אומר שיש אפקט עם כיוון מסוים להתערבות).
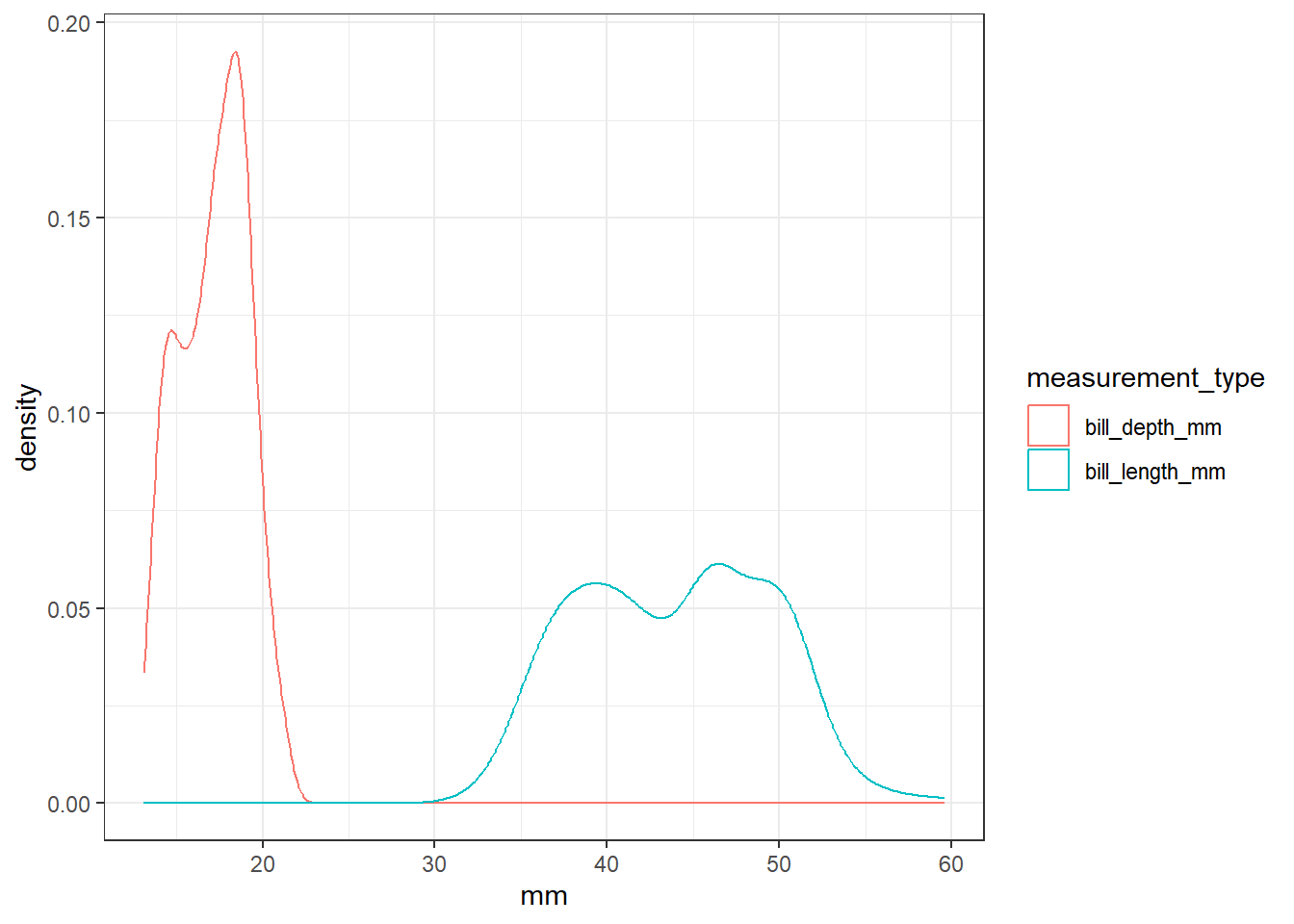
נמחיש זאת על ידי השוואה בין אורך המקור לעומק המקור (bill_length_mm, bill_depth_mm). מדובר בשני מדגמים, אך הם קשורים ביניהם (משום שכל תצפית של אורך קשורה לתצפית מסוימת של עומק).
ראשית נשתמש בתרשים על מנת להמחיש את ההתפלגויות של המשתנים:
penguins %>%mutate(specimen =seq_along(species)) %>%select(specimen, bill_length_mm, bill_depth_mm) %>%pivot_longer(cols =-specimen, names_to ="measurement_type", values_to ="mm") %>%ggplot(aes(x = mm, color = measurement_type)) +geom_density()
Warning: Removed 4 rows containing non-finite outside the scale range
(`stat_density()`).
כפי שניתן לראות, ההתפלגויות שונות מאוד (האורך ארוך משמעותי מן העומק), ולכן ניתן להעריך שגם מבחן המובהקות יגלה זאת.
Paired t-test
data: penguins$bill_length_mm and penguins$bill_depth_mm
t = 79.505, df = 341, p-value < 2.2e-16
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
26.10846 27.43306
sample estimates:
mean difference
26.77076
הפלט מאוד דומה לפלטים שכבר ראינו (שימו לב שבכותרת Paired t-test המציין שמדובר במבחן מזווג), ובמקרה זה המבחן מובהק סטטיסטית.
ניתן לראות שההבדל בין אורך לעומק המקור עומד על 26.1 ועד 27.4 מ”מ, ברווח בר סמך של 95%.
Tip
היעזרו בפקודה t.test על מנת לבחון את ההשערה שההבדל בין אורך לעומק המקור עומד על 26.5 מ”מ.
לשם כך השתמשו במבחן מזווג עם הארגומנט mu (מה צריך להיות ערכו של הארגומנט?).
6.4 מבחן לשיוויון שונויות
השונות מתארת את פיזור התצפיות, והיא מעניינת ממגוון סיבות. בפרט, כפי שראינו בפקודת t.test לעיתים נרצה להגדיר לפקודה האם להניח שונויות שוות או שונות (וזה משפיע על המבחן, כלומר הנוסחאות, שהפקודה מבצעת). באפשרותנו להשתמש בפקודה var.test על מנת לבחון האם השונויות של שני מדגמים שוות (השערת האפס הינה שיוויון השונויות, וההשערה האלטרנטיבית היא שהשונויות אינן שוות).
המבחן שבו נשתמש בוחן את היחס בין השונויות, וכן הוא מניח ששתי השונויות הן של משתנים מקריים הלקוחים מהתפלגות נורמלית. המבחן נקרא מבחן F. נדגים את המבחן על השונות של אורך המקור של Gentoo לעומת אורך המקור של Chinstrap.
F test to compare two variances
data: bill_length_mm by species
F = 1.174, num df = 67, denom df = 122, p-value = 0.4411
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.778208 1.818704
sample estimates:
ratio of variances
1.174017
שימו לב שאופן השימוש בפקודה מאוד דומה לאופן השימוש בפקודה t.test (ראו בחלק של מדגמים לא מזווגים). להלן הסבר על פלט הפקודה:
השורה הראשונה של הפלט מציינת שמדובר במבחן F.
בשורה השלישית אנחנו רואים את נתוני המבחן (הסטטיסטי, דרגות חופש במונה ובמכנה, וכן את ה-p-value המחושב) כפי שניתן לראות p-value > 0.05, ולכן לא ניתן לדחות את השערת האפס שהשונויות שוות בין שני המדגמים.
בשורה הבאה ניתן לראות מה בחן המבחן (ההשערה האלטרנטיבית היא שהיחס בין השונויות שונה מ-1).
לאחר מכן מופיע רווח בר סמך ליחס בין השונויות \((0.778, 1.819)\). ניתן לראות רווח בר הסמך כולל את הערך 1 (שקול לאי-דחיית השערת ה-0).
בשורה האחרונה הפקודה מספקת לנו אמד ליחס בין השונויות (1.17).
6.5 מבחן חי-בריבוע (טיב התאמה, אי-תלות)
מבחן חי-בריבוע (\(\chi^2\)) יכול לשמש אותנו לשתי מטרות מרכזיות (שתיהן בוחנות את השונות):
מבחן טיב התאמה
מבחן אי-תלות
כאמור, אין הכוונה להיכנס בספר זה לתיאוריה העומדת מאחורי המבחן, אך בבסיסה עומד העיקרון של פירוק המדגם לתאים סטטיסטיים, שבכל אחד “ספירה של תצפיות”. הסטטיסטי שמבוסס על ספירה זו של תצפיות הוא סכום של ריבועי משתנים מקריים, ולכן מתפלג חי-בריבוע.
6.5.1 מבחן טיב התאמה
במבחן טיב התאמה אנחנו מנסים לראות האם התפלגות מסוימת הנצפית בנתונים האמפיריים תואמת להתפלגות אחרת תיאורתית. השערת האפס הינה שההתפלגות האמפירית לקוחה מתוך התפלגות תיאורתית ידועה, לעומת ההשערה האלטרנטיבית (שאינה לקוחה מהתפלגות זו). לכן מכונה המבחן טיב-התאמה (או באנגלית goodness-of-fit).
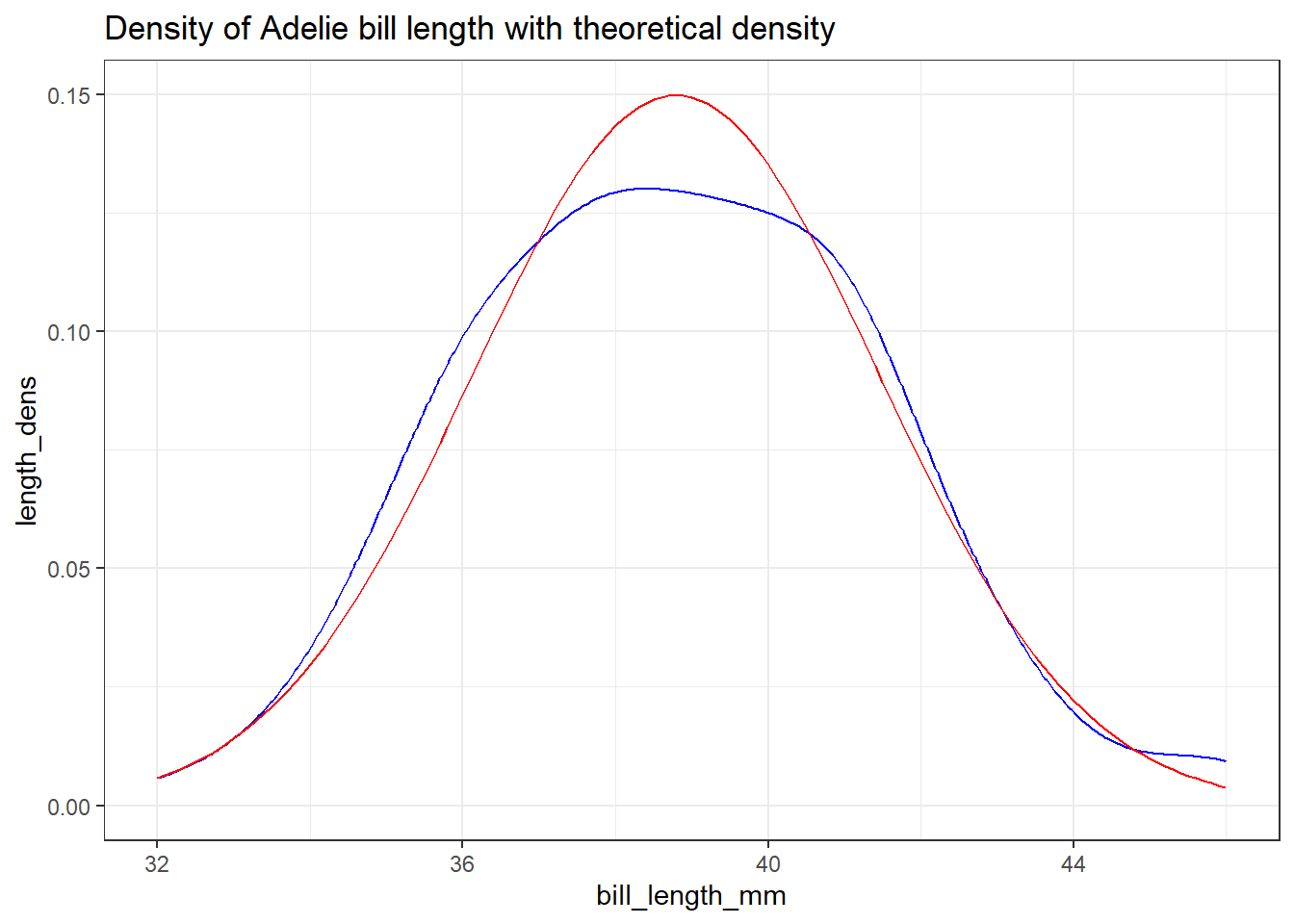
נחזור לדוגמה על זן ה-Adelie ונבחן את ההשערה שהתפלגות אורך המקור לקוחה מהתפלגות נורמלית.
נלביש את ההתפלגות הנצפית וההתפלגות התיאורתית (עם ממוצע וסטיית תקן לפי הממוצע וסטיית התקן הנאמדים מהנתונים).
length_mu <-mean(adelie$bill_length_mm)length_sd <-sd(adelie$bill_length_mm)theoretical_bill_length <-tibble(x =seq(32, 46, 0.1)) %>%mutate(length_dens =dnorm(x = x,mean = length_mu,sd = length_sd))ggplot(adelie, aes(x = bill_length_mm)) +geom_density(color ="blue") +geom_line(data = theoretical_bill_length, inherit.aes =FALSE,aes(x = x, y = length_dens), color ="red") +ggtitle("Density of Adelie bill length with theoretical density")
השלבים שבוצעו בקוד כללו ראשית בניית טבלה של צפיפות של ההתפלגות הנורמלית עם ממוצע 38.79, וסטיית תקן 2.66, הם האמדים מהנתונים האמפיריים של תוחלת וסטיית תקן אורך המקור של פינגויינים מזן Adelie. הפונקציה dnorm משמשת לחישוב הצפיפות הנורמלית.
לאחר מכן השתמשנו בggplot, שאליו הוספנו שכבה נוספת של geom_line אשר לא משתמשת בדאטה הראשי (adelie) אלא בטבלה המשנית שחישבנו בשלב קודם (theoretical_bill_length). השתמשנו בארגומנטים data = theoretical_bill_length וב-inherit.aes = FALSE , על מנת להנחות את הפקודה של geom_line להשתמש בדאטה שונה, ובהגדרות אסתטיקה שונות.
התוצאה נראית כמו שני גרפי צפיפויות דומים אחד לשני, עם חריגה מסוימת (באדום הצפיפות התיאורתית ובכחול האמפירית). דומים, אבל לא זהים. האם הם “שונים מספיק” על מנת שנדחה את השערת האפס (שהם אותה ההתפלגות)?
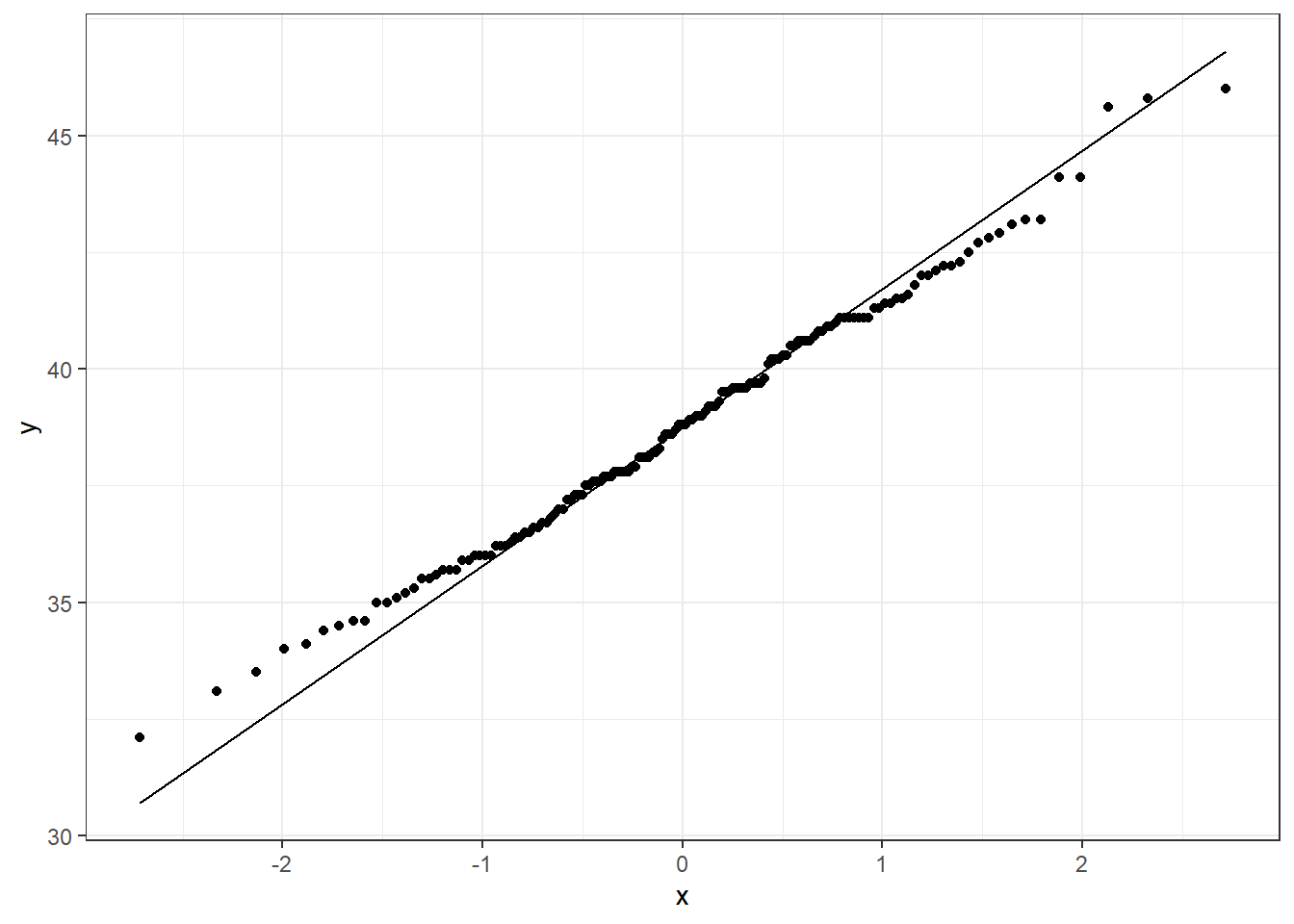
צעד אחד מקדים לפני שנבצע את מבחן טיב ההתאמה, הוא לבנות תרשים הנותן לנו כלי להשוות בין התפלגויות. תרשים מסוג Q-Q-Plot.
6.5.1.1 תרשים Q-Q-Plot
בתרשים מסוג Q-Q-Plot המחשב מציב אחוזונים של שתי התפלגויות כנקודות במרחב (התפלגות אחת בציר X והשניה בציר Y). אם הנקודות המוצגות מתלבשות על אלכסון הדבר מעיד על כך שהן מגיעות מאותה התפלגות. ככל שהנקודות מתרחקות מהאלכסון, הדבר מעיד על כך שההתפלגויות אינן זהות. התרשים מהווה כלי ויזואלי שיכול לתמוך את התיאור של מבחן טיב ההתאמה.
בתרשים אנחנו יכולים לראות שמרבית הנקודות שבמרכז ההתפלגות פחות-או-יותר חופפות עם הקו שמוצג בתרשים, אך בקצוות (במיוחד בקצה התחתון) רואים שלהתפלגות האמפירית (המוצגת בציר y) יש ערכים מעט גבוהים מהמצופה ונשאלת השאלה האם חריגה זו מספיקה על מנת לדחות את ההשערה שאורך המקור מתפלג נורמלית (הנקודות שנמצאות מתחת ל-1- בציר ה-x נמצאות מעל הקו הישר המוצג בתרשים). כעת נפעיל מבחן סטטיסטי על מנת לבחון את טיב ההתאמה של ההתפלגות להתפלגות נורמלית עם הפרמטרים של תוחלת וסטיית תקן, כפי שמחושבים מהנתונים של אורך המקור.
6.5.1.2 ביצוע מבחן טיב ההתאמה
במבחן טיב ההתאמה עלינו לחלק את ההתפלגות האמפירית לתאים סטטיסטיים (שבדרך כלל מקובל לסמן ב-$O_i$ מלשון Observed), ולהשוות למול תאים בהתפלגות התיאורתית (שמקובל לסמן באות \(E_i\) מלשון Expected). אחד התנאים לשימוש במבחן הוא שבכל תא סטטיסטי מספר התצפיות הצפוי יהיה לפחות 5 תצפיות.
Chi-squared test for given probabilities
data: observed_expected_counts$observed
X-squared = 1.6432, df = 4, p-value = 0.801
ראשית נקבעו הגבולות של הקבוצות בהתפלגות (הדיסקרטיזציה, כלומר יצירת התפלגות בדידה), כך שההתפלגות תכיל את כל תוצאות ההתפלגות האפשריות מ-0 ועד 1.
החלק השני של הקוד מייצר את טבלת התצפיות בפועל ואת מספר התצפיות הצפוי (על ידי חישוב ההסתברות מתוך הממוצע וסטיית התקן של המדגם), והכפלה בסך התצפיות במדגם.
לאחר מכן אנחנו משתמשים בפקודה chisq.test. שימו לב שלמעשה לא השתמשנו במספר התצפיות הצפוי אלא בהתפלגות שלהם (הארגומנט p), שמעיד מה ההסתברות לקבל דגימות בתאים הסטטיסטיים הנבחנים.
במקרה זה קיבלנו p.value=0.801 כלומר לא ניתן לדחות את השערת האפס שההתפלגות הנדונה היא התפלגות נורמלית (לכן נאמר שיש בסיס להתייחס להתפלגות כהתפלגות נורמלית).
Note
במרבית ספרי הסטטיסטיקה תמצאו את הנוסחה הבאה עבור מבחן חי-בריבוע.
ראשית מחשבים את הסטטיסטי: \[
X=\sum_{i=1}^l\frac{\left(O_i-E_i\right)^2}{E_i}
\]
כאשר \(l\) הוא מספר התאים הסטטיסטיים (בדוגמה הקודמת 5), ומספר דרגות החופש בהתפלגות יהיה \(df=l-1\).
לאחר מכן מחשבים את ה-p-value לפי ערכו של הסטטיסטי:
\[
\Pr\left(X>\chi^2_{df}\right)
\]
הפקודה שהרצנו למעשה מבצעת חישוב זה בדיוק. ניתן להדגים זאת על ידי ביצוע החישוב באופן ישיר.
מבחן אי-תלות משמש אותנו על מנת להבחין האם שני משתנים מקריים כלשהם הם בעלי תלות מסוימת או לא, כאשר שניהם משתנים קטגוריאליים. נדגים את השימוש במבחן: בנתוני הפינגויינים שעמם אנחנו עובדים. בדוגמאות ישנם מספר משתנים קטגוריאליים (זן, אי, מין, ושנת המדידה שחרף היותו מספרי ניתן להתייחס אליו גם כקטגוריה). נרצה לבחון באמצעות מבחן אי-תלות האם יש קשר בין זן הפינגויינים לבין שנת המדידה: כלומר האם החוקרים שאספו את הדאטה נתנו דגשים על איסוף נתונים של זנים מסוימים בשנים מסוימות או שעבדו באופן אחיד בדגימת פינגויינים מכל שלושת הזנים בכל תקופת איסוף הדאטה בשנים 2007-2009. נתחיל ביצירת תרשים שיציג את התפלגות הזנים בכל שנת דגימה.
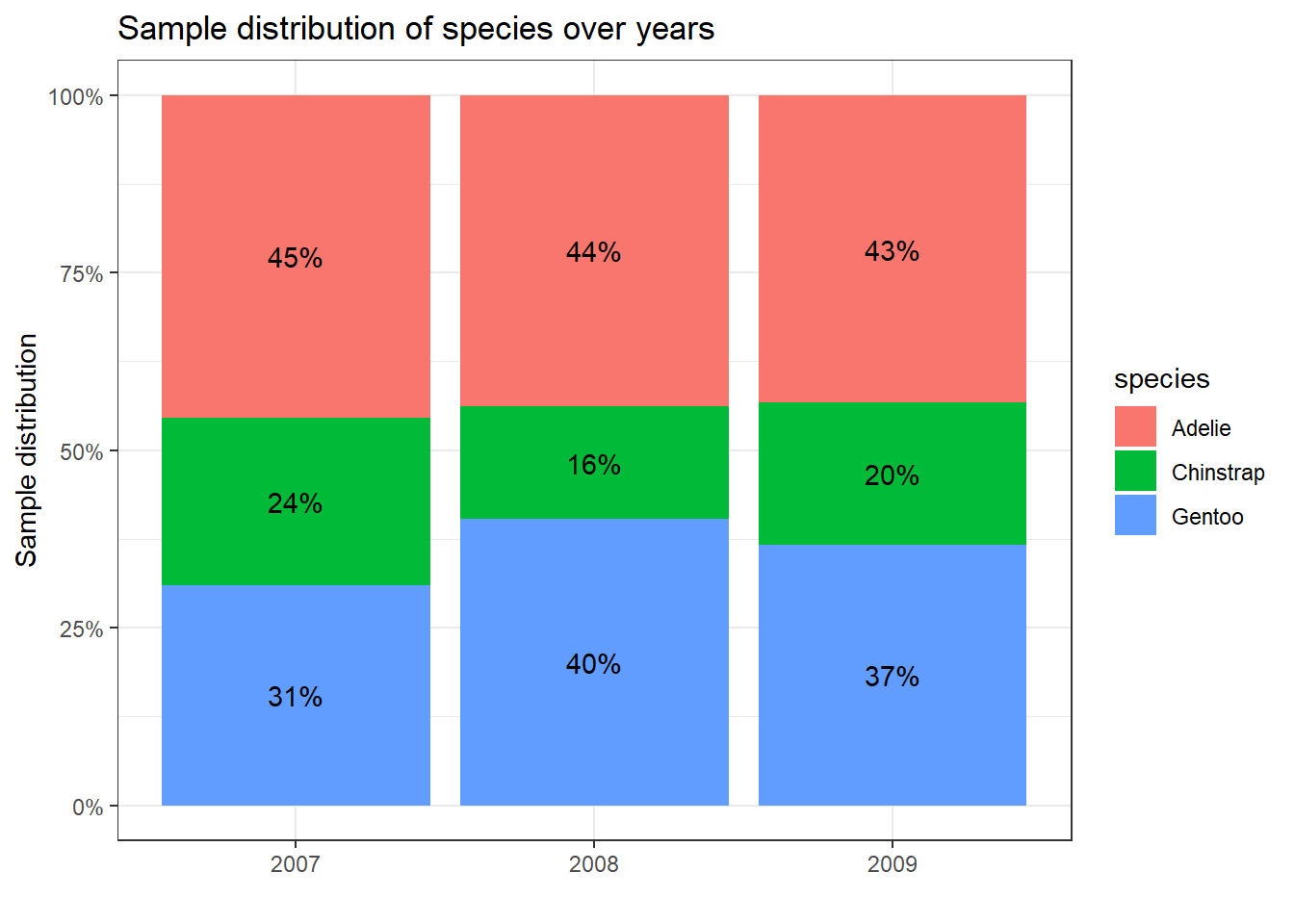
penguins %>%count(year, species) %>%group_by(year) %>%mutate(prop = n/sum(n)) %>%ggplot(aes(x =factor(year), y = prop, fill = species)) +geom_col(position =position_fill()) +scale_y_continuous(labels = scales::percent) +ylab("Sample distribution") +xlab("") +ggtitle("Sample distribution of species over years") +geom_text(aes(label = glue::glue("{round(prop*100)}%")),position =position_fill(vjust =0.5), show.legend =FALSE)
כפי שניתן להבחין בתרשים, ישנם הבדלים מסוימים. לדוגמה, בשנת 2007 רק 31% מהדגימות הם של פינגויינים מזן Gentoo לעומת שנת 2008 שם 40% מהדגימות הן מזן Gentoo. השערת האפס שלנו היא שהמשתנה שנה והמשתנה זן הפינגויין הם בלתי תלויים, וההשערה האלטרנטיבית הינה שהם תלויים.
גם במקרה זה נשתמש בפונקציה chisq.test. נדגים שתי שיטות להפעיל את הפונקציה, שתיהן מביאות אותה התוצאה. השיטה הראשונה היא להזין את הפונקציה בשני וקטורים של המשתנים:
independent_chisqtest <-chisq.test(x = penguins$year, y = penguins$species)independent_chisqtest
Pearson's Chi-squared test
data: penguins$year and penguins$species
X-squared = 3.2156, df = 4, p-value = 0.5224
השיטה השניה היא ראשית לבנות מטריצה (בגודל 3 על 3 במקרה שלנו, כי לכל משתנה שלושה ערכים אפשריים), ואז להזין אותה לפונקציה כך:
תוצאות המבחן בשני המקרים כמובן זהות, משום שבוריאציה הראשונה הפונקציה מבצעת באופן פנימי את הספירה שביצענו בוריאציה השניה. הסיבה שהצגנו את שתי האפשרויות היא שלעיתים הנתונים שיש בידינו הם רק הספירות ולא הפקטורים המקוריים (ואז נהיה חייבים להשתמש באפשרות השניה).
מבחינת פרשנות- ניתן לראות שערך ה-p.value הינו 0.5224, ולכן לא ניתן לדחות את השערת האפס (כלומר ייתכן שהמשתנים בלתי תלויים).
6.6 מבחן פרופורציות
במקרים בהם אנחנו רוצים להשוות פרופורציות בין שתי קבוצות (שני מדגמים), או לבצע מבחן השערות על פרופורציות בקבוצה מסוימת, נשתמש במבחן פרופורציות.
6.7 מבחן פרופורציות עם מדגם יחיד
ראשית נדגים מבחן פרופורציות עם מדגם יחיד: נבצע מבחן סטטיסטי על פרופורצית הפינגויינים ששוקלים מעל 4 ק”ג, ונבחן האם פרופורציה זו שונה באופן מובהק מ-50%.
כפי שניתן לראות יש 165 פרטים עם משקל מתחת ל-4 ק”ג, ו-177 פרטים עם משקל מעל 4 ק”ג. סה”כ 342 פרטים. נשתמש בפקודה prop.test על מנת לבחון את ההשערה של חלוקה שווה (פרופורציה 50%).
penguin_prop <-prop.test(x =177, n =342, p =0.5)penguin_prop
1-sample proportions test with continuity correction
data: 177 out of 342, null probability 0.5
X-squared = 0.3538, df = 1, p-value = 0.552
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.4632340 0.5714533
sample estimates:
p
0.5175439
כפי שניתן לראות בפלט הפקודה, ערך ה-p-value הינו 0.552, ולכן לא ניתן לדחות את השערת האפס של חלוקה חצי/חצי. רווח בר סמך לפרופורציה של הפינגויינים בעלי משקל מעל 4 ק”ג נמצא בין 0.463 ועד 0.571.
נקודות למחשבה
נסו לבצע את המבחן עם פרופורצית הפרטים מתחת למשקל 4 ק”ג. האם מתקבלת אותה התוצאה? מה שונה ומה דומה בפלט? הסבירו.
6.8 מבחן פרופורציות לשני מדגמים
נבצע מבחן המשווה את שיעור הפרטים בעלי משקל מעל 4.5 ק”ג המשווה בין זן ה-Gentoo ליתר הזנים.
twosample_prop <-prop.test(x =c(11, 107), n =c(219, 123))twosample_prop
2-sample test for equality of proportions with continuity correction
data: c(11, 107) out of c(219, 123)
X-squared = 230.56, df = 1, p-value < 2.2e-16
alternative hypothesis: two.sided
95 percent confidence interval:
-0.8921516 -0.7472291
sample estimates:
prop 1 prop 2
0.05022831 0.86991870
כפי שניתן לראות על פי תוצאות המבחן, יש שיעור של כ-5% מהפינגויינים שאינם מזן Gentoo שמשקלם מעל 4.5 ק”ג, לעומת 87% מהפינגויינים שהם כן מזן Gentoo ומשקלם מעל 4.5 ק”ג. הבדל זה מובהק סטטיסטית עם p-value < 2.2e-16 (כלומר קטן מהמספר הקטן ביותר שהמחשב יכול להציג).
רווח בר סמך להפרש בין אחוזים אלו נמצא בין 0.747 ועד 0.892 (בשורה בפלט זה מופיע בסימן שלילי משום שהפקודה מחסרת את הפרופורציה הראשונה מהשניה ובמקרה זה הפרופורציה הראשונה נמוכה מהשניה - 11 מתוך 219 לעומת 107 מתוך 123).
הקשר שבין מבחני פרופורציות ומבחן חי-בריבוע לאי-תלות
נסו להשתמש במבחן חי-בריבוע chisq.test על מנת לבצע את מבחן הפרופורציות מהסעיף הקודם
רמז: עליכם לבנות מטריצה 2*2 כאשר השורות הן מעל/מתחת למשקל שנקבע והעמודות הם שני הסוגים של הפינגויינים (כן/לא מסוג Gentoo.
האם קיבלתם את אותה התוצאה כמו במבחן הפרופורציות? (מה שונה ומה דומה?)
הוסיפו ארגומנט למבחן הפרופורציות: correct = FALSE, ארגומנט זה מבטל תיקון (מניפולציה) שמבצעת הפונקציה. האם כעת התוצאות זהות?
6.9 מבחן קולמוגורוב-סמירנוב (KS test) להתפלגות
מבחן קולמוגורוב-סמירנוב משמש להשוואה בין שתי התפלגויות, בדומה למבחן חי-בריבוע לטיב התאמה, אך הוא אינו דורש התפלגויות בדידות (כפי שמבחן חי-בריבוע דורש).
אפשר להפעיל אותו על מנת להשוות בין שתי התפלגויות רציפות נתונות או בין התפלגות רציפה נתונה לבין התפלגות רציפה תיאורתית. לדוגמה, נשווה את אורך המקור של פינגויינים מזן Adelie להתפלגות רציפה תיאורתית נורמלית עם תוחלת 38.79, וסטיית תקן 2.66:
ks_test_output <-ks.test(adelie$bill_length_mm, "pnorm", mean = length_mu, sd = length_sd)
Warning in ks.test.default(adelie$bill_length_mm, "pnorm", mean = length_mu, :
ties should not be present for the one-sample Kolmogorov-Smirnov test
ks_test_output
Asymptotic one-sample Kolmogorov-Smirnov test
data: adelie$bill_length_mm
D = 0.042489, p-value = 0.948
alternative hypothesis: two-sided
תוצאת המבחן במקרה זה הינה שלא ניתן לדחות את השערת האפס (שההתפלגות הינה התפלגות נורמלית עם תוחלת וסטיית תקן כפי שחושבו מהדאטה). בדומה לממצא שקיבלנו ממבחן טיב ההתאמה מסוג חי-בריבוע.
הודעת האזהרה של פלט המבחן ks.test
במסגרת המבחן שהרצנו קיבלנו הודעת אזהרה:
ties should not be present for the Kolmogorob-Smirnov test.
מבחן קולמוגורוב-סמירנוב משתמש בסטטיסטי שונה מהסטטיסטיים שהצגנו עד כה (סטטיסטי t וסטטיסטי חי-בריבוע). במסגרת חישוב הסטטיסטי של מבחן קולמוגורוב-סמירנוב מסודרים הערכים שבמדגם. אם מחושבת ההתפלגות האמפירית ומשוות להתפלגות התיאורתית. הודעת האזהרה מעידה על כך שיש ערכים זהים שלא ניתן לסדרם, אך המבחן עדיין עובד ומחזיר את תוצאת החישוב. ככל שבהתפלגות האמפירית ישנם הרבה ערכים זהים, זה מהווה אינדיקציה לכך שההתפלגות אינה רציפה, וייתכן שמבחן טיב התאמה עשוי להיות מתאים יותר (ואשר משווה להתפלגות בדידה).
6.10 סידור הפלט של מבחני השערות
בכל המקרים שבחנו בפרק זה הזנו למבחנים נתונים בפורמט מסודר של טבלאות (אם הפעלנו את ארגומנט ה-data וה-formula או בפורמט של וקטורים). תוצאות המבחנים הוצגו כפלט טקסטואלי, אך בפועל היו רשימה (list) עם רכיבים שונים שניתן להפריד אותם. לדוגמה במבחן האחרון שהרצנו (ks.test) ניתן היה לקרוא רק לערכו של ה-p-value על ידי שימוש בקוד: ks_test_output$p.value. ישנה חבילה הנקראת broom ובה פקודה הנקראת tidy שמסייעת לנו להפוך את הפלט של הפקודות השונות לטבלה (פחות או יותר אחידה).
נדגים זאת על חלק מהפלטים שראינו בפרק (כולל סידור של פורמט העמודות בטבלה באמצעות חבילת gt).
התחלנו במבחני השערות על תוחלת של מדגם יחיד, מבחני השערות על תוחלת עבור שני מדגמים לא-מזווגים ועבור שני מדגמים מזווגים.
למדנו על מבחן לשיוויון שונויות, ומבחני חי-בריבוע לטיב התאמה ולאי-תלות.
לאחר מכן למדנו להשתמש במבחני פרופורציות (מדגם יחיד, ושני מדגמים), ועל מבחן קולמוגורוב-סמירנוב להתפלגות.
לבסוף למדנו כיצד ניתן להעביר את הפלט של המבחנים לפלט טבלאי מסודר.
המדריך העברי למשתמש ב-R נכתב על ידי עדי שריד בהוצאת מכון שריד
Walpole, Ronald E, Raymond H Myers, Sharon L Myers, and Keying Ye. 1993. Probability and Statistics for Engineers and Scientists. Vol. 5. Macmillan New York.