בפרק זה נלמד על השימוש בחבילת purrr לצורך בניית לולאות. הפונקציות שזמינות לנו בחבילה זו מחליפות את רוב השימושים בהם נרצה להפעיל את for (שהוזכרה בפרק 2).
היתרונות בשימוש בפונקציות מחבילת purrr על פני לולאות for הינם:
מהירות - יש מקרים בהם השימוש בפונקציות אלו יניב תוצאות מהירות משמעותית מהשימוש בלולאות for
קריאות - הקוד יוצא הרבה יותר ברור
שילוביות - ניתן לשלב את הפונקציות הללו בתוך תחביר של tidyverse יחסית בקלות
הכללה למקביליות - קל להפוך את הקוד למקבילי באמצעות הרחבות (חבילת furrr)
הפונקציה המרכזית ב-purrr היא map. היא מקבלת שני ארגומנטים: האובייקט שעליו רוצים להריץ את הלולאה (וקטור או רשימה), והפונקציה שרוצים להריץ על אך איבר באובייקט שהוכנס בארגומנט הראשון.
נראה דוגמה לשימוש ב-map על גבי הדאטה של penguins ליצירת שלושה מודלי רגרסיה לינארית, עבור כל זן פינגויינים.
9.1 סידור הדאטה
ראשית ניקח את הדאטה, ונעביר אותו לפורמט עבודה נוח:
Rows: 3
Columns: 2
Groups: species [3]
$ species <fct> Adelie, Gentoo, Chinstrap
$ data <list> [<tbl_df[152 x 5]>], [<tbl_df[124 x 5]>], [<tbl_df[68 x 5]>]
בעמודה האחרונה שנוצרה לנו בטבלת penguins_nested (שנקראת data), קיבלנו את הדאטה עבור כל אחד מסוגי הפינגויינים (זו למעשה טבלה בת שלוש שורות ושתי עמודות, העמודה השניה מכילה טבלאות עם המשתנים המקוריים שהיו בדאטה, למעט משתנה ה-Species).
9.2 הדגמה לבניית מודלים
כעת נבנה מודל רגרסיה לינארית, לחיזוי bill_length_mm על בסיס כל יתר המשתנים:
penguins_nested_lm <-map(penguins_nested$data,function(x){lm(bill_length_mm ~ ., data = x)})
כעת קיבלנו שלושה מודלים, הנה המודל הראשון:
summary(penguins_nested_lm[[1]])
Call:
lm(formula = bill_length_mm ~ ., data = x)
Residuals:
Min 1Q Median 3Q Max
-6.3921 -1.4294 -0.0276 1.4291 5.3977
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 26.3151542 5.9906398 4.393 2.18e-05 ***
bill_depth_mm -0.0121755 0.1868468 -0.065 0.9481
flipper_length_mm 0.0388034 0.0305910 1.268 0.2067
body_mass_g 0.0011487 0.0006183 1.858 0.0653 .
sexmale 2.1964106 0.5473780 4.013 9.71e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.124 on 141 degrees of freedom
(6 observations deleted due to missingness)
Multiple R-squared: 0.3814, Adjusted R-squared: 0.3639
F-statistic: 21.74 on 4 and 141 DF, p-value: 5.464e-14
תרגיל למחשבה
נסו להריץ את הפקודה של בניית המודלים על הדאטה אך מבלי שמבוצעת בו הבחירה:
מתקבלת הודעת שגיאה. איזה משתנה יצר את הבעיה ומדוע?
צורות נוספות להגדרת פונקציה
שימו לב שבתוך פקודת ה-map הגדרנו את הפונקציה בארגומנט השני, בתוך הקוד “inline”.
ניתן היה להגדיר פונקציה מחוץ ל-map ואז פשוט להכניס את השם שלה, כך:
create_model <-function(x){lm(bill_length_mm ~ ., data = x)}penguins_nested_lm <-map(penguins_nested$data, create_model)
כמו כן, סינטקס נוסף להגדרת פונקציות ב-“inline” הוא שימוש בתו ~, באופן הבא:
penguins_nested_lm <-map(penguins_nested$data,~ {lm(bill_length_mm ~ ., data = .x)})
שימו לב בחלק השני לשימוש ב-.x אשר מסמל בהגדרה זו היכן יש להכניס את הרכיב עצמו מתוך האובייקט עליו מבצעים את הלולאה.
9.3 סידור תוצאות המודלים
ניתן להשתמש בפקודה broom::tidy על מנת לקבל את תוצאות הפקודה באופן מסודר. במקרה זה נשתמש בסינטקס מלא של tidyverse ונטמיע את השימוש בפקודה map בתוך פקודת mutate שמופעלת על עמודת ה-data שראינו קודם.
בתוצאת הטבלה ניתן לראות 15 שורות, עבור כל מין של פינגויינים יש חמש שורות כאשר כל שורה מתייחסת לערכיו של משתנה ספציפי (מקדם, טעות תקן, ערך הסטטיסטי, ורמת מובהקות). ניתן לסדר את הטבלה לפורמט רחב באופן הבא, נניח שיציג מקדמים ורמת מובהקות בלבד:
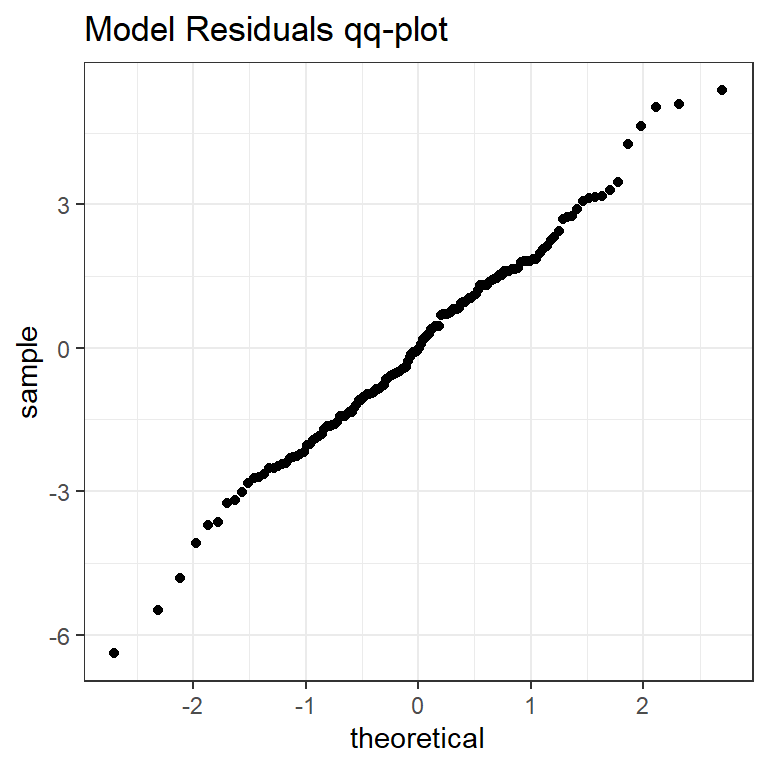
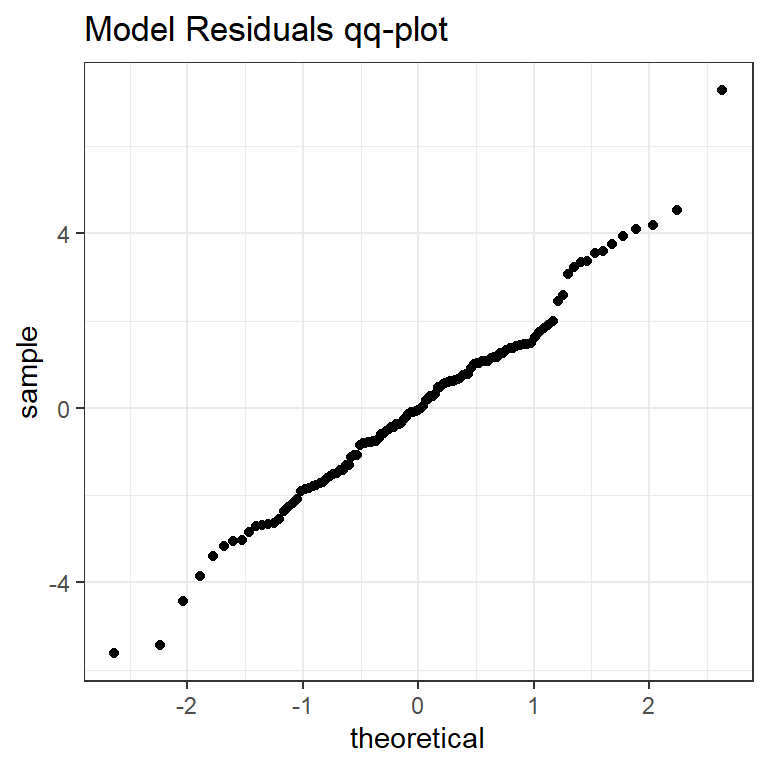
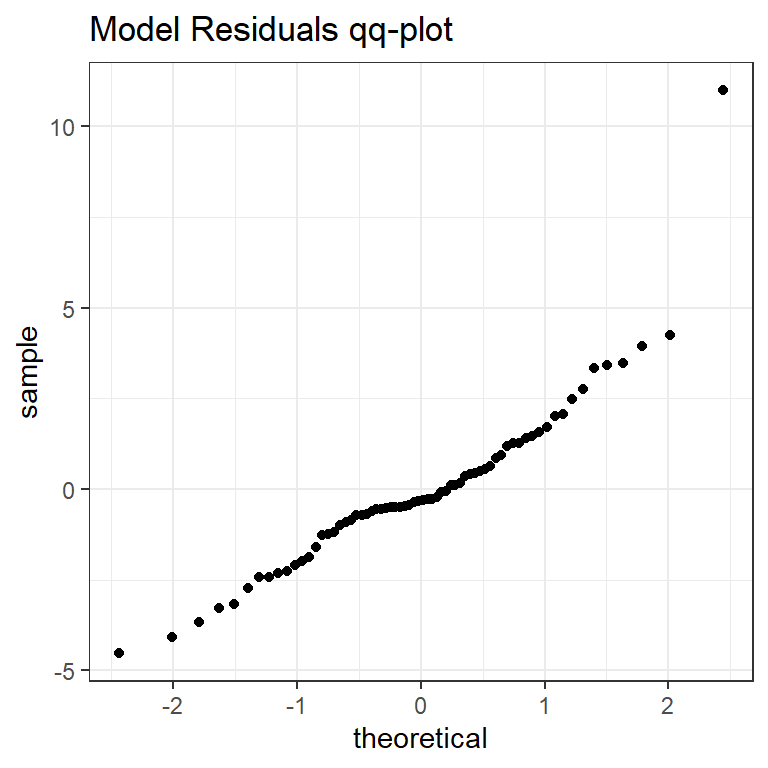
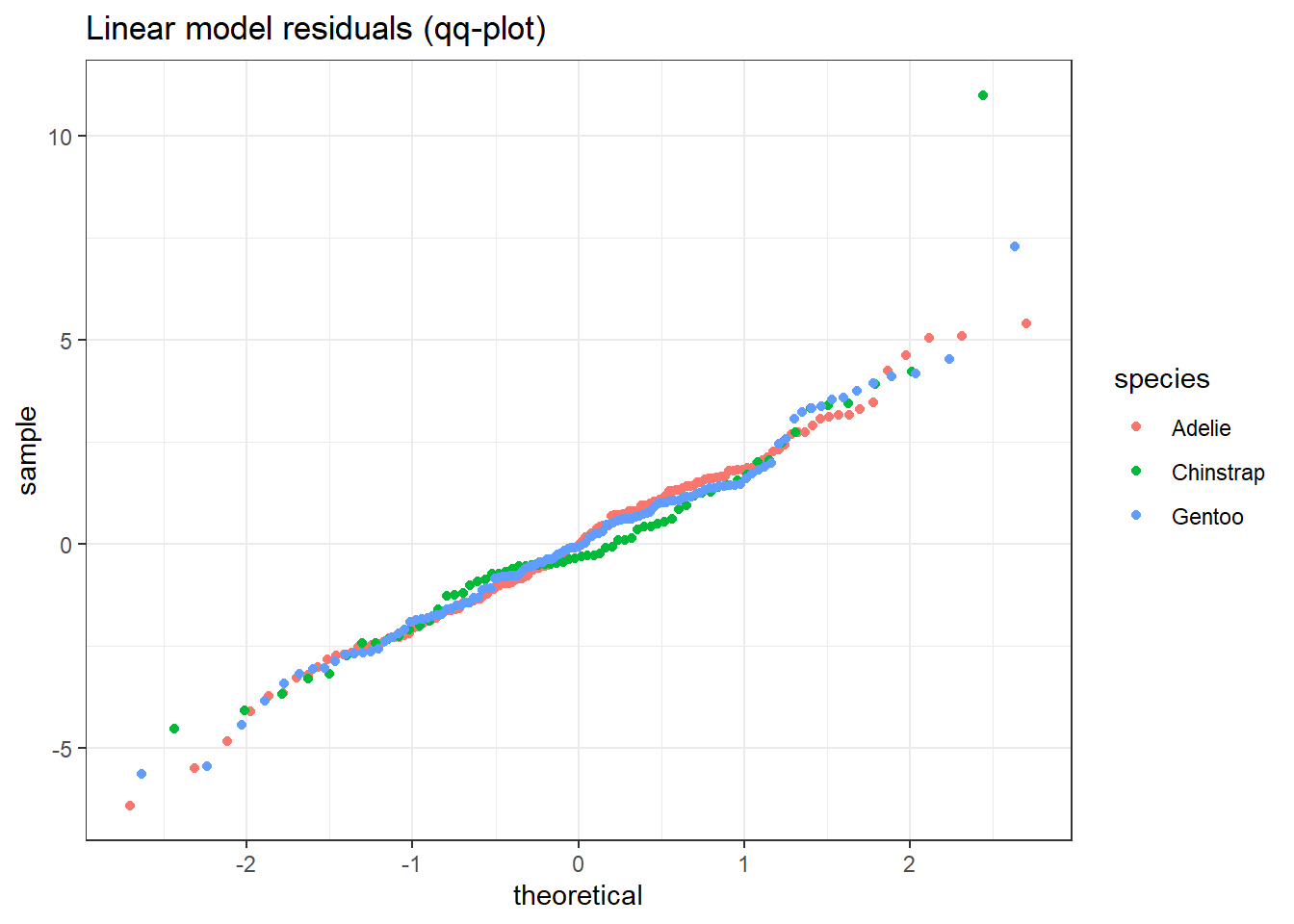
כתבו קוד, תוך שימוש ב-map לצורך סידור השאריות של המודלים, על מנת לייצר את התרשים הבא:
9.5 פונקציות נוספות בחבילת purrr
פונקצית map היא אולי בין הפונקציות השימושיות ביותר בחבילת purrr, אך ישנן מספר פונקציות נוספות שימושיות:
הפונקציה walk שימושית כאשר רוצים להריץ לולאה לא בשביל תוצאת החישוב אלא בשביל הפעולה של הפונקציה. לדוגמה, במקרה שרוצים להפיק דוחות מרובים של RMarkdown, או אם נניח רוצים לשלוח הרבה מיילים באוטומציה (הפונקציה הבסיסית שולחת מייל והוקטור עליו רצים הוא וקטור של כתובות מייל);
הפונקציה map2 והפונקציה pmap מאפשרות להריץ לולאה על פני מספר רכיבים. הלולאה רצה על השילובים הקיימים של הרכיבים לפי הסדר (אבל לא על ההצלבה ביניהם);
פונקציה נוספת שימושית היא list_rbind כאשר הפונקציה map מחזירה רשימה שבה רכיבים בודדים ורוצים להפוך אותה לוקטור של ערכים (לדוגמה, כחלק מסינטקס של tidyverse);
ארגומנט נוסף שימושי בפונקציה map הוא progress המאפשר להציג את ההתקדמות של הלולאה (“progress bar”). מספיק להוסיף ארגומנט progress=True והפקודה תציג את ההתקדמות, בהנחה שהפעולה לוקחת מספיק זמן.
9.6 סיכום
בפרק זה למדנו על השימוש בחבילת purrr ובפרט בפונקציה map בחבילה זו. השימוש בחבילה זו מאפשר לנו לבנות לולאות אשר נראות מסודרות יותר מלולאות for, בעלות פוטנציאל לרוץ מהר יותר, ומשתלבות יפה בסינטקס של tidyverse. בפרק ראיתם “טעימה קטנה” מהשימוש בפונקציות, אך ככל שתיתקלו במקרים כאלו ותנסו את הפונקציות הללו תיווכחו לראות שהן מועילות מאוד. נדרש קצת זמן להתרגל אליהן, אך זה שווה את המאמץ.
המדריך העברי למשתמש ב-R נכתב על ידי עדי שריד בהוצאת מכון שריד